The question
People make consequential decisions, career changes, financial commitments, life transitions, with very little structured support. Generic LLM chatbots haven't filled the gap. They answer for users, replacing reasoning with instruction. They make the decision-maker more dependent, not more capable.
What if you built a coaching system designed not to answer? An LLM whose pedagogy is restraint. And how would you measure whether it actually produced better decisions, when "good decision" is famously slippery?
Decision Coach is my answer to those questions. It's a deployed system at decisioncoach.io. It's also a working paper. The contribution that matters isn't the chat interface. It's the measurement instrument.
How I measured it
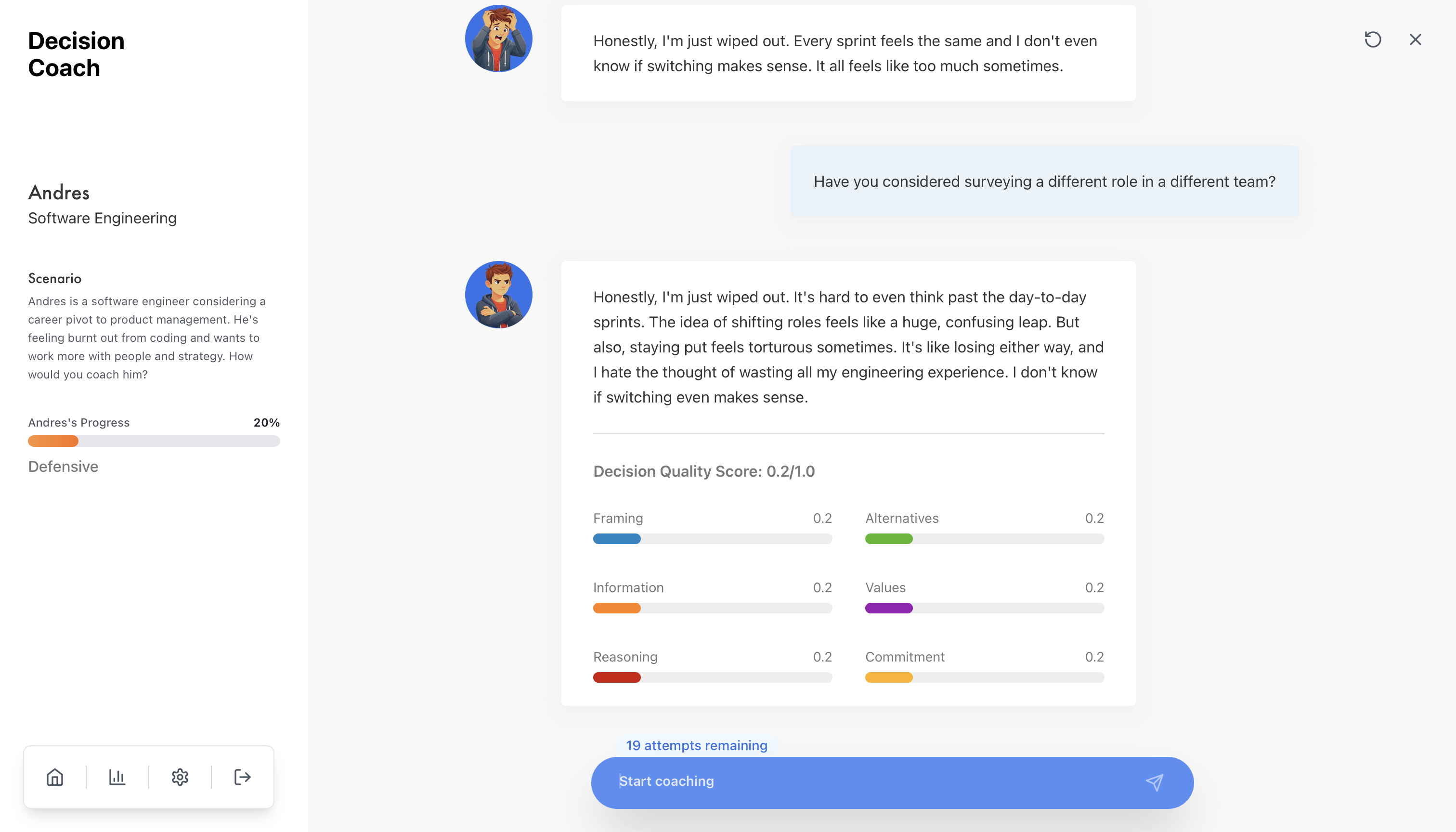
Decision quality is hard to evaluate after the fact because outcome and process get conflated. A bad decision can produce a good outcome through luck. A sound decision can produce a bad outcome through circumstance. Decision Quality Science separates them by scoring the process across six elements: Frame, Values, Alternatives, Information, Reasoning, and Commitment.
I built an automated assessment engine that scores each user turn against this six-dimension rubric on a 0 to 1 scale, with behaviorally anchored levels at each band. The aggregate is intentionally not a mean. It's the minimum across dimensions, the weakest link. A coaching session with strong framing but no commitment-to-action is incomplete, and a mean-based score would hide that.
Calibration against expert practitioners showed acceptable preliminary inter-rater reliability (r = 0.71). Broader validation against multiple human annotators is ongoing.
Why automated scoring matters: turn-level human coding doesn't scale past about 50 sessions per study wave. The LLM evaluator replaces roughly 100 hours of human coding per wave, which is what makes the rest of the research design feasible.
The reward-hacking story.
The technical anecdote that anchors the whole methodology came early. In the first version, I used a single LLM instance to both generate Jamie's responses and score the user's turns. Scores looked excellent. When I split them into two separate LLM calls with separate prompts and separate contexts, average scores dropped about 0.10. That delta is the methodological argument for separation. A generator that also evaluates inflates its own scores. It's a textbook reward-hacking failure mode, and it's the moment Decision Coach became a research artifact rather than a demo.
The system
The system is built around the measurement, not around the chat. The architecture has two LLMs in separate contexts:
- Persona LLM ("Jamie"). Simulates a college sophomore navigating a major-switching decision. Jamie has a backstory, an emotional state machine (confused, uncertain, thoughtful, confident), and cognitive constraints encoded in the system prompt. Jamie refuses to advance through the Decision Chain stages until the current dimension has been adequately covered. The refusal is the pedagogy.
- Evaluation LLM. Scores each user turn against the DQ rubric in a separate context, returning per-dimension scores and rationale.
Five personas were shipped; one (Jamie) was used in the pilot. The system enforces a 10-turn session limit, which transforms coaching from open-ended conversation into purposeful practice.
Stack. React frontend; Node/Express backend; Supabase Postgres with row-level security for participant data isolation; OpenAI GPT-4o for both agents; Python (pandas) for analysis. The data pipeline is IRB-compliant, with research-code pseudonymization and no PII in research exports.
There is also a prototype AI-to-AI feedback loop, RLAIF-style: an evaluator critiques the persona's coaching and proposes prompt refinements, with a human validation gate to prevent drift. This was not used in the pilot results below.
What the pilot showed
IRB-approved pilot. 52 participants, 75 sessions, 68 with full turn-level scoring. College students, mixed undergrad and grad. Mean engagement: 11 turns per session.
Mean DQ Overall went from 0.145 at first turn to 0.366 at last turn. That's a within-session improvement of +0.220 (+151% relative). 91% of sessions (62 of 68) showed improvement; 4% declined; 4% were unchanged.
Important caveat: this is within-session improvement, not a between-condition causal effect. The falsifiable test (not-knowing persona vs. all-knowing persona) is in the planned full study (target n ≈ 200, between-subjects, with a 2 to 4 week longitudinal follow-up for skill transfer).
The honest research note.
I started with a hypothesis that Commitment would be the weakest dimension at session-end. Per-dimension finals showed something different:
Binary thinking is the ceiling. Emotional and value exploration is natural. That's quantitative evaluation overturning a design assumption, which is exactly what a properly designed measurement instrument should do.
Why this matters
The defensible contribution isn't the chat UI. It's the rubric plus LLM judge as a measurement instrument that scales beyond what human coding can support. The same instrument is, in principle, portable: it can evaluate human decision coaches, compare coaching approaches, or train practitioners. It operationalizes "good judgment" into observable, scoreable behaviors.
The system-level claim is more pointed: a coaching LLM that refuses to answer can produce measurable within-session learning. That doesn't yet establish that the not-knowing persona is causally responsible (the planned between-subjects study is what tests that). But it does demonstrate that a measurement instrument designed to detect process improvement can detect it.
What's next
- Run the full study (n ≈ 200, between-subjects: not-knowing vs. all-knowing persona, with mediation by user agency and moderation by educational level). This is the falsifiable test.
- Longitudinal follow-up at 2 to 4 weeks to test whether coaching skills transfer to participants' own decisions.
- Comprehensive inter-rater reliability against multiple human annotators to validate the LLM judge beyond the preliminary r = 0.71.
- Roll out the four additional personas (international students with visa constraints, returning adult students balancing education and family, students facing financial pressure, and others) to test cross-scenario skill transfer.
Cite
Rodriguez, C. (2026). DecisionCoach: A Multi-Agent Conversational System for Developing Decision-Making Competence Through Coaching Practice. Working paper.